

티스토리 뷰
카프카 생태계
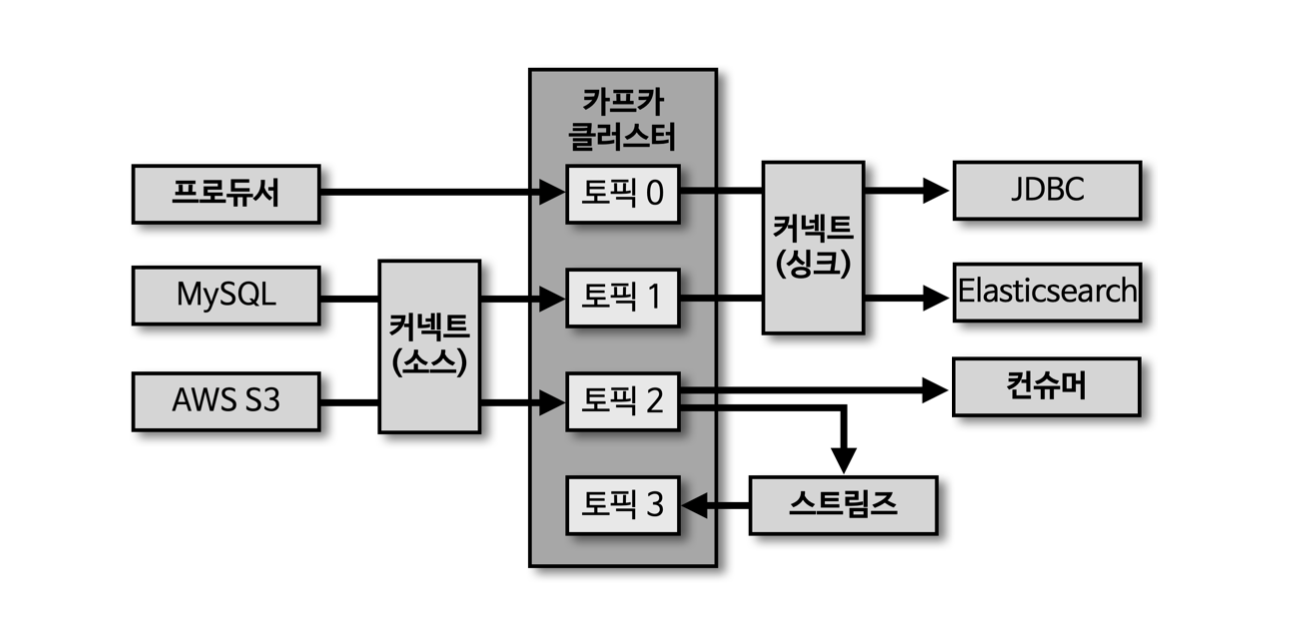
- 프로듀서: 토픽으로 데이터(메세지)를 발행한다.
- 컨슈머: 토픽에서 데이터(메세지)를 소비한다.
- 토픽: 목적에 따라서 생성된 데이터(메세지)이다.
- 스트림즈: 프로세싱을 통해서 토픽에 존재하는 데이터를 처리하고, 다시 토픽에 넣는 역할을 수행한다.
- 커넥트: 데이터 파이프라인을 운영하는 가장 핵심적인 툴이다.
- 소스 커넥트: 특정 DB나 AWS S3와 같은곳에서 데이터(메세지)를 가져와서 토픽으로 발행한다.
- 싱크 커넥트: 타켓 애플리케이션으로 데이터(메시지)를 소비한다.

주키퍼
- 카프카 클러스터를 운영하기 위해서 반드시 필요한 애플리케이션이다.
- 카프카 2.x 버전까지는 반드시 주키퍼가 필요하고, 3.x 버전부터는 주키퍼가 없더라도 운영이 가능하지만, 아직까지는 완벽하게 주키퍼를 대체하지 못하는 부분이 있으므로 여러 기업에서는 주키퍼가 존재하는 카프카를 운영하고 있다.
브로커
- 카프카 클라이언트와 데이터를 주고받기 위해 사용하는 주체이자, 데이터를 분산 저장하여 장애가 발생하더라도 안전하게 사용할 수 있도록 도와주는 애플리케이션이다.
- 카프카 브로커 서버 1대로도 기본 기능이 실행되지만, 데이터를 안전하게 보관하고 처리하기 위해 3대 이상의 브로커 서버를 1개의 클러스터로 묶어서 운영한다.
- 카프카 클러스터로 묶인 브로커들은 프로듀서가 보낸 데이터를 안전하게 분산 저장하고 복제하는 역할을 수행한다.
브로커의 역할
컨트롤러
- 클러스터의 다수 브로커 중 한 대가 컨트롤러의 역할을 수행한다.
- 다른 브로커들의 상태를 체크하면서 브로커가 클러스터에서 빠지는 경우, 해당 브로커에 존재하는 리더 파티션을 재분배한다.
데이터 삭제
- 다른 메세징 플랫폼과 다르게 컨슈머가 데이터를 가져가더라도 토픽의 데이터는 삭제되지 않고, 컨슈머나 프로듀서가 데이터 삭제를 요청할 수도 없다.
- 오직 브로커만이 데이터를 삭제할 수 있다.
- 데이터 삭제는 파일 단위로 이루어지는데, 이 단위를 “로그 세그먼트”라고 하고, 이 세그먼트에는 다수의 데이터가 들어 있기 때문에 일반적인 데이터베이스처럼 특정 데이터 삭제가 불가능하다.
컨슈머 오프셋 저장
- 토픽이 특정 파티션으로부터 데이터를 가져가서 처리한 뒤, 해당 파티션의 어느 레코드까지 가져갔는지 확인하기 위해 오프셋을 커밋(위치를 기록하기 위함)한다.
- 커밋된 오프셋은 자동으로
_consumer_offserts토픽에 저장된다. - 저장된 오프셋을 토대로 컨슈머 그룹은 다음 레코드를 가져가서 처리한다.
그룹 코디네이터
- 컨슈머 그룹의 상태를 체크하고 파티션을 컨슈머와 매칭되도록 분배하는 역할
- 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상 동작하는 컨슈머로 할당하여 끊임없이 데이터가 처리되도록 도와준다.
- 이렇게 파티션을 컨슈머로 재할당하는 과정을 리밸런스(
rebalance)라고 한다.
데이터 저장

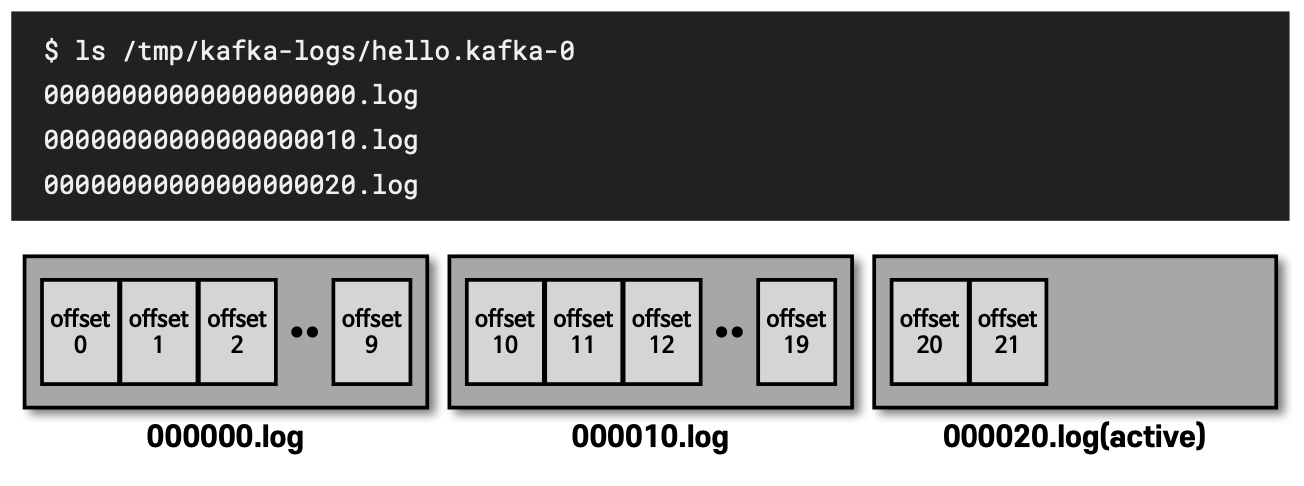
- 카프카를 실행할 때
config/server.properties의log.dir옵션에 정의한 디렉토리에 데이터를 저장한다.- 토픽 이름과 파티션 번호의 조합으로 하위 디렉토리를 생성하여 데이터를 저장한다.
- 위 이미지를 보면
hello.kafka토픽의 0번 파티션에 존재하는 데이터를 확인할 수 있다. log에는 메시지와 메타데이터를 저장한다.index는 메시지의 오프셋을 인덱싱한 정보를 담은 파일이다.timeindex파일에는 메시지에 포함된timestamp값을 기준으로 인덱싱한 정보가 담겨 있다.
로그와 세그먼트
log.segment.bytes: 바이트 단위의 최대 세그먼트 크기 지정, 기본 값은 1GBlog.roll.ms(hours): 세그먼트가 신규 생성된 이후 다음 파일로 넘어가는 시간 주기, 기본 값은 7일
액티브 세그먼트
- 가장 마지막 세그먼트 파일(쓰기가 일어나고 있는 파일)을 액티브 세그먼트라고 한다.
- 액티브 세그먼트는 브로커의 삭제 대상에 포함되지 않는다.
- 액티브 세그먼트가 아닌 세그먼트는
retention옵션에 따라 삭제 대상으로 지정된다.
세그먼트와 삭제 주기 (cleanup.policy=delete)
retention.ms(minutes, hours): 세그먼트를 보유할 최대 기간, 기본 값은 7일retention.bytes: 파티션당 로그 적재 바이트 값, 기본 값은 -1(지정하지 않음)log.retention.check.interval.ms: 세그먼트가 삭제 영역에 들어왔는지 확인하는 간격, 기본 값은 5분
세그먼트의 삭제(cleanup.policy=delete)
- 카프카에서 데이터는 세그먼트 단위로 삭제가 발생하기 때문에 로그 단위(레코드 단위)로 개별 삭제는 불가능하다.
- 로그(레코드)의 메시지 키, 메시지 값, 오프셋, 헤더 등 이미 적재된 데이터에 대해서 수정 또한 불가능하기 때문에 데이터를 적재(프로듀서)할 때 또는 데이터를 사용(컨슈머)할 때 데이터를 검증하는 것이 좋다.
cleanup.policy=compact

- 메시지 키 별로 해당 메시지 키의 레코드 중 오래된 데이터를 삭제하는 정책을 뜻한다.
- 삭제(
delete) 정책과 달리 일부 레코드만 삭제될 수 있다.
테일/헤드 영역
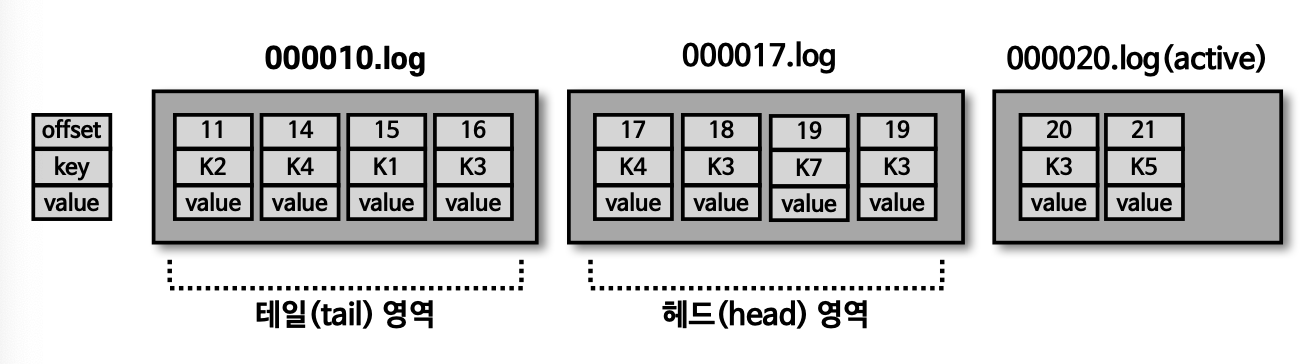
- 테일 영역: 클린(
clean)로그 라고도 표현하고, 압축 정책에 의해 압축이 완료된 레코드들이며, 중복 메시지 키가 없다. - 헤드 영역: 더티(
dirty)로그라고도 표현하고, 압축 정책이 되기 전 레코드들이며, 중복된 메시지 키가 있다.
min.cleanable.dirty.ratio
- 데이터의 압축 시작 시점은
min.cleanable.dirty.ratio옵션 값을 따른다. min.cleanable.dirty.ratio옵션 값은 액티브 세그먼트를 제외한 세그먼트에 남아 있는 테일 영역의 레코드 개수와 헤드 영역의 레코드 개수의 비율을 뜻한다.- 0.5로 설정하면 테일 영역과 헤드 영역의 레코드 개수가 동일할 경우에 압축이 실행된다.
- 너무 크게 설정하면 데이터가 너무 많이 적재되어 용량을 차지하므로 용량 효율이 좋지 않다.
- 반대로 너무 작게 설정하면 최신의 데이터만 유지할 수 있지만 브로커에 부담을 줄 수 있다.
복제 (Replication)

- 클러스터로 묶인 브로커 중, 일부에 장애가 발생하더라도 데이터를 유실하지 않고 안전하게 사용하기 위함이다.
- 데이터 복제는 파티션 단위로 이루어지고, 토픽을 생성할 때 파티션의 복제 개수(
replication factor)도 같이 설정되는데, 직접 옵션을 선택하지 않으면 브로커에 설정된 옵션 값을 따라간다. - 복제된 파티션은 리더와 팔로워로 구성되며, 프로듀서나 컨슈머와 직접 통신하는 파티션을 리더, 나머지 복제 데이터를 가지고 있는 파티션을 팔로워라고 한다.
- 팔로워 파티션들은 리더 파티션의 오프셋을 확인하여 현재 자신이 가지고 있는 오프셋과 차이가 나는 경우, 리더 파티션으로부터 데이터를 가져와서 자신의 파티션에 저장한다.
- 복제 개수만큼의 저장 용량이 증가하지만, 복제를 통해 데이터를 안전하게 사용할 수 있다는 장점때문에 운영할 때 2이상의 복제 개수를 정하는 것이 중요하다.
브로커에 장애가 발생한 경우
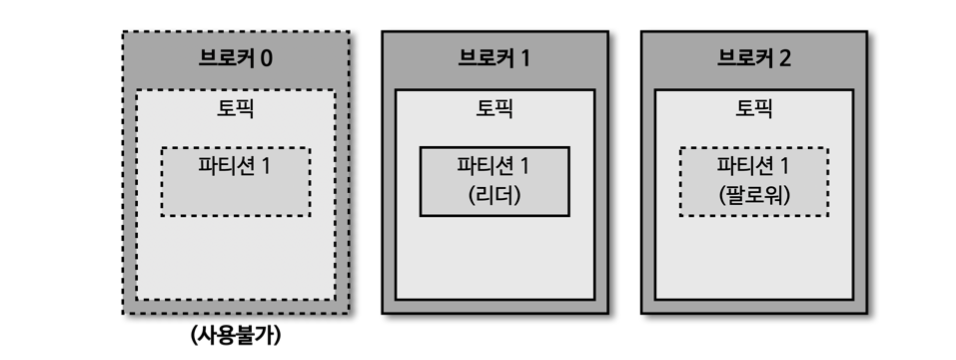
- 브로커가 다운되면 팔로워 파티션 중 하나가 리더 파티션으로 승격된다.
- 그로 인해 데이터가 유실되지 않고, 프로듀서나 컨슈머와 지속적으로 데이터를 주고 받을 수 있다.
'Apache Kafka' 카테고리의 다른 글
| [Apache Kafka] 프로듀서 (Producer) (0) | 2023.04.24 |
|---|---|
| [Apache Kafka] 카프카 기본 개념 (0) | 2023.04.12 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 알고리즘
- 자료구조
- Real MySQL
- 스프링 부트
- 구현
- kotlin
- 정렬
- mysql 8.0
- Algorithm
- webflux
- MySQL
- Spring
- 스프링부트
- 릿코드
- 인프런
- Java
- 노마드코더
- 김영한
- 스프링
- 코틀린
- 북클럽
- leetcode
- 파이썬
- 코테
- 자바
- 문자열
- 백준
- 그리디
- spring boot
- 데이터베이스
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
글 보관함